مجازی سازی
مجازی سازی - مجازی سازی دسکتاپ - مجازی سازی شبکه - مجازی سازی دیتا سنتر - راهکار های مجازی سازیمجازی سازی
مجازی سازی - مجازی سازی دسکتاپ - مجازی سازی شبکه - مجازی سازی دیتا سنتر - راهکار های مجازی سازیسرور بلید c7000
سرور بلید c7000

سرور بلید c7000 برای محیط های اینترپرایز و کسب و کار هایی طراحی شده است که در آن ها نیاز به توان پردازشیِ بالا است. این دستــگاه 10U از فضای رک شما را اشغال می کند. انکلـوژر BladeSystem c7000 نیازهای زیرساخت های پاور، سرمایشی و I/O را برای پشتیبانی از Blades Server و اتصالات داخلی و اجزای ذخیره سازی برای چندین سال فراهم می کند. این محصول فراتر از سرورهای Blade می باشد. هر انکلوژر قابلیت پشتیبانی از چندین نسل از سرورها را دارا است. HP OneView ادغامی از سرور، ذخیره ساز، شبکه و مدیریتی واحد است که می تواند به عنوان یک محیط یکپارچه مدیریت شود. این نرم افزار مدیریت سرور، ذخیره ساز و شبکه را در پنل مدیریتی خود ترکیب نموده و یک پلتفرم مدیریتی یکپارچه را در اختیار شما قرار می دهد. انکلوژر c7000 مدیران شبکه را قادر می سازد تا به راحتی با اضافه کردن تیغه های بیشتر توان پردازش بیشتری داشته باشند. به این ترتیب سازمان ها پس از صرف هزینه اولیه، هزینه های کمتری را برای افزایش توان پردازشی و انرژی پرداخت می نمایند.
c7000 Enclosure شامل اجزاء زیر می باشد:
- Hot-plug Power Supplies
- ماژول Power Input
- Hot-plug HPE Active Cool Fans
- ماژول Optional Redundant BladeSystem Onboard Administrator
بعد از انتخاب انکلوژر و اجزای کلیدی مربوط به آن می توان سایر اجزاء های مورد نیاز را اضافه کرد . در ادامه به این موارد اشاره شده است :
- ماژول های Interconnect
- سرور های HPE ProLiant و Integrity Server Blades
- Expansion Blades
- HPE OneView یا نرم افزار مدیریت HPE Insight Control
توجه داشته باشیم که : Blade سرورهای نسل 10 ، از Insight Control پشتیبانی نمی کنند .
BladeSystem c7000 Enclosure حداکثر 16 عدد سرور Blade و حداکثر 8 عدد تیغه Compute، استوریج یا Workstation به علاوه Storage Interconnects و شبکه های Redundant، را ارائه می دهد . این محصول همچنین شامل MidPlane مولتی-ترابیت با سرعت بالا می باشد که جهت برقراری اتصالات Wire-Once سرورهای Blade به شبکه و ذخیره ساز اشتراکی مورد استفاده قرار می گیرد . توان برقی که در این انکلوژر به کار می رود از طریق منبع تغذیه Backplane تأمین می شود و این تضمین را می دهد که ظرفیت کامل آن برای تمام تیغه ها (Blades) قابل دسترس باشد.
منبع : Network-Services
بکاپ گیری از اطلاعات
بکاپ گیری از اطلاعات
یکی از اساسی ترین مسایل برای فهم پشتیبان گیری (backup) و بازیابی (recovery) ، مفهومِ سطوح backup است و اینکه هر یک از این سطوح چه معنایی دارند.
فقدانِ درک صحیح از اینکه این سطوح چه هستند و چگونه به کار گرفته می شوند، منجر شده است که سازمان ها تجربه ناخوشایندی از پهنای باند و فضای ذخیره سازی به هدر رفته ای داشته باشند که جهت از دست نرفتن داده های مهم در بکاپ گیری از اطلاعات به آنها تحمیل می شود. همچنین درک این مفاهیم به هنگام انتخاب محصولات یا خدمات حفاظت از اطلاعات بسیار ضروری است.
Full backup
پشتیبان گیریِ کامل، شامل همه داده های کل سیستم می شود. بکاپ کامل از Windows system ، باید کپی هر یک از فایل ها بر روی هر درایو از ماشین یا VM را در برگیرد.
تنها چیزی که در پشتیبان گیری کامل حذف می شود، فایل هایی هستند که از طریق پیکربندی مستثنا می شوند. به طور مثال، اکثر ادمین های سیستم تصمیم می گیرند که دایرکتوری هایی را که در طول بازگردانی ارزشی ندارند (به طور مثال، /boot یا /dev) یا دایرکتوری های شامل فایل های موقتی (به طور مثال، C:\Windows\TEMP در ویندوز، یا /tmp در لینوکس) حذف شوند.
در مورد اینکه فرآیند بکاپ گیری از اطلاعات شامل چه فایل هایی باید شود، دو رویکرد وجود دارد: از همه چیز بکاپ بگیرید و چیزهایی را که می دانید به آنها نیاز ندارید را حذف کنید، یا اینکه تنها چیزی را که می خواهید از آن بکاپ بگیرید، انتخاب کنید. اولین رویکرد گزینه ای امن تر است و رویکرد دوم نیز منجر به صرفه جویی در فضای سیستم بکاپ گیری از اطلاعات شما خواهد شد. برخی معتقدند که بکاپ گیری از فایل های اپلیکیشن همچون دایرکتوری های شامل SQL Server یا Oracle ، بیهوده است و به سادگی در طول فرآیند بازگردانی، اپلیکیشن را دوباره بارگذاری می کنند. مشکل رویکرد اخیر این است که احتمال دارد شخصی داده ای ارزشمند را در یک دایرکتوری قرار دهد که برای پشتیبان گیری انتخاب نشده است. به فرض اگر شما تنها دایرکتوریِ home/ یا D:\Data را برای پشتیبان گیری برگزینید، چگونه سیستمِ بکاپ تشخیص خواهد داد که شخصی اطلاعاتی مهم را در دیگر دایرکتورها ذخیره کرده است؟ به همین دلیل، با وجود اینکه رویکرد اول فضای زیادتری را اشغال می کند، پشتیبان گیری از همه چیز روشی امن تر می باشد و تنها فایلهایی که نیازی ندارید، حذف می شوند. البته اگر شما یک محیطِ به شدت کنترل شده داشته باشید که در آن همه داده ها در مکانی مشخص بارگذاری شده باشند و راهکار هماهنگ شده ی مناسبی برای جابجایی سیستم عامل و اپلیکیشن ها در فرآیند بازگردانی داشته باشید، استفاده از راهکار دوم برایتان موثر خواهد بود.
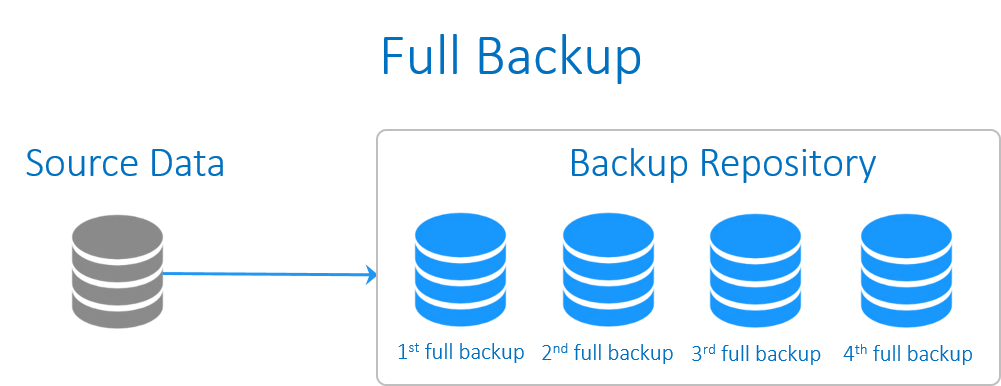
از آنجایی که حجم عظیمی از داده ها باید کپی شوند، در این فرآیند زمان بسیاری صرف خواهد شد (در مقایسه با انواع دیگر از روش های بکاپ گیری از اطلاعات ، این روش 10 برابر زمان بیشتری را صرف می کند). در نتیجه در هر نوبتِ پشتیبان گیری، بارکاری قابل ملاحظه ای به شبکه تحمیل می شود و با عملیات روتینِ شبکه شما تداخل پیدا می کند. همچنین بکاپ گیری از اطلاعات به طور کامل حجم بالایی از فضای ذخیره سازی را نیز اشغال می کند.
به همین دلیل است که بکاپ گیری از اطلاعات به طور کامل تنها به صورت دوره ای گرفته خواهد شد و آن را با انواع دیگر بکاپ ترکیب می کنند.
فواید بکاپ گیری از اطلاعات به طور کامل:
- ریکاوری سریعِ داده ها به هنگام رخدادِ یک disaster
- مدیریت بهتر ذخیره سازی، از آنجایی که تمام مجموعه داده ها در یک فایل بکاپِ واحد ذخیره می شوند
معایب بکاپ گیری از اطلاعات به طور کامل:
با وجود اینکه بکاپ گیری از اطلاعات به طور کامل، مزیت های بالا را برای شما به ارمغان می آورد اما شامل نقاط ضعف بسیاری نیز هست:
- اجرای بکاپِ کامل، زمان بسیاری زیادی را به خود اختصاص می دهد
- شما نیاز به یک ذخیره ساز با ظرفیت بسیار بالا خواهید داشت تا بتواند همه بکاپ های شما را دربر گیرد
- از آنجایی که هر فایلِ full backup شامل کل مجموعه داده های شماست (که اغلب محرمانه هستند)، اگر این داده ها به دسترسی شخصی فاقدِ صلاحیت برسند، کسب و کار شما دچار مخاطره می شود. هر چند اگر راهکار بکاپِ شما از ویژگی data protection پشتیبانی نماید، می توان از این خطرات پیشگیری نمود.
incremental backup (بکاپ افزایشی)
بکاپِ افزایشی معمولا از داده هایی پشتیبان می گیرد که از زمان آخرین بکاپِ گرفته شده (هر نوعی از بکاپ که باشد)، تغییری روی آنها صورت گرفته باشد. گرفتن یک بکاپِ کاملِ اولیه از پیش شرط های ایجادِ بکاپِ افزایشی است. و بسته به سیاست های ذخیره سازیِ بکاپ، پس از یک دوره زمانی معین به یک full backup جدید برای تکرار این سیکل نیاز است.
برخی از این نوع بکاپ ها، بکاپ های file-based هستند به این معنا که از همه فایلهایی که نسبت به آخرین زمان بکاپ تغییر کرده باشند، بکاپ تهیه می شود. در حالی که ما به روش های مختلف می کوشیم تا تاثیر I/O ناشی از بکاپها بر روی سرور (به خصوص به هنگام پشتیبان گیری از VM ها) را کاهش دهیم، در این شیوه بکاپ گیری از اطلاعات با چالشی در این مورد مواجه خواهیم شد. چرا که پشتیبان گیری از یک فایل 10GB که تنها 1 MB از آن تغییر کرده است، چندان کارآمد نیست.
به دلیل ناکارآمدی در شیوه file-based، اکثر کمپانی ها به سمت بکاپ افزایشیِ block-based رفته اند که در آن تنها از بلاک های تغییر یافته، بکاپ گرفته می شود. رایجترین روش برای انجام آن هنگامی است که از محصولات نرم افزاری بکاپ تهیه می شود، به طور مثال از VMware یا Hyper-V با استفاده از API هر یک از آنها، می توان پشتیبان تهیه نمود. هر App یک API مناسب خود را اعلام می کند که بکاپ افزایشیِ block-based را انجام می دهد.
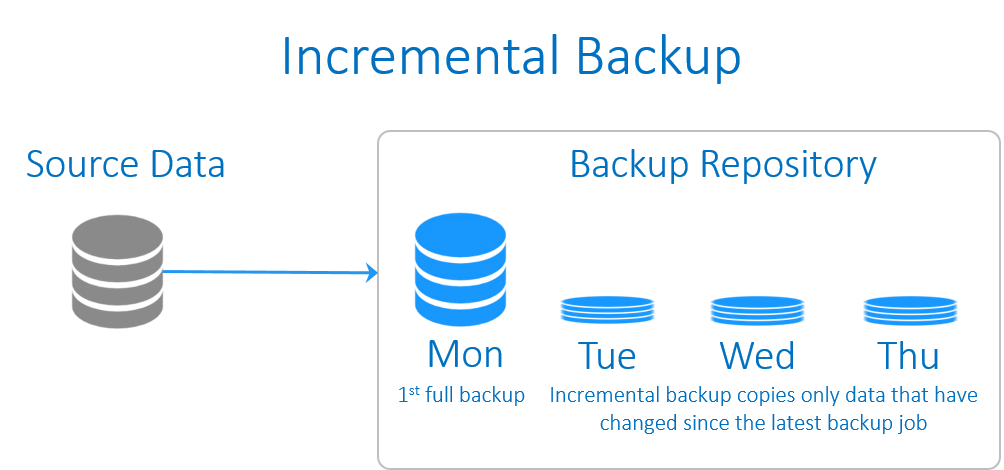
بکاپ افزایشی از سرعت بالایی برخوردار است و در مقایسه با full backup، به فضای ذخیره سازیِ بسیار کمتری نیاز دارد. اما از آنجایی که در این شیوه به بازگردانیِ آخرین بکاپِ کامل و علاوه بر آن کل زنجیره بکاپ های افزایشی نیاز است، فرآیند ریکاوریِ آن مدت زمان بیشتری به طول می انجامد. اگر یکی از بکاپ های افزایشی در این زنجیره بکاپ از دست برود یا صدمه ببیند، ریکاوری کامل آن غیر ممکن خواهد شد.
فواید بکاپ افزایشی:
- از آنجایی که تنها از داده های افزوده شده بکاپ تهیه می شود، فرآیند بکاپ گیری از اطلاعات سرعت بسیار بالایی دارد
- به فضای ذخیره سازی کمتری نیاز است
- هر کدام از این بکاپ های افزایشی یک نقطه بازیابی مجزا هستند
معایب بکاپ افزایشی:
- هنگامی که شما نیاز داشته باشید، هم بکاپ کامل و هم همه ی بکاپ های افزایشی متوالی را بازگردانید، سرعت بازگردانیِ کامل داده ها پایین است
- بازگردانیِ موفق داده ها به عدم نقص در تمامیِ بکاپ های افزایشی موجود در زنجیره وابسته است
Differential backup (بکاپ تفاضلی)
Differential backup راهکاری بینابینِ بکاپ افزایشی و بکاپ کامل است. همچون بکاپ افزایشی، در اینجا نیز نقطه آغاز بکاپ گیری از اطلاعات وجود یک بکاپ کامل اولیه است. سپس از همه داده ها که از زمان آخرین بکاپ کامل (full backup) تغییر کرده باشند، بکاپ گرفته می شود. در مقایسه با بکاپ های افزایشی، differential backup اکثر داده هایی که در بکاپ های اخیر تغییر کرده اند را ذخیره نمی کند، تنها داده هایی ذخیره می شوند که نسبت به بکاپ کامل اولیه تغییر کرده اند. بنابراین بکاپ کامل، نقطه مبنا برای بکاپ گیری متوالی است. در نتیجه بکاپ differential در مقایسه با بکاپ افزایشی، سرعت بازگردانی داده را افزایش می دهد چرا که تنها به دو قطعه بکاپ اولیه و آخرین بکاپِ differential نیاز است. این نوع از بکاپ گیری از اطلاعات در زمان استفاده از درایوهای tape رواج بسیاری داشت، چرا که تعداد tape های مورد نیاز برای بازگردانی را کاهش می داد. بازگردانی (restore) نیاز به آخرین بکاپ کامل در کنار آخرین differential backup و incremental backup دارد.
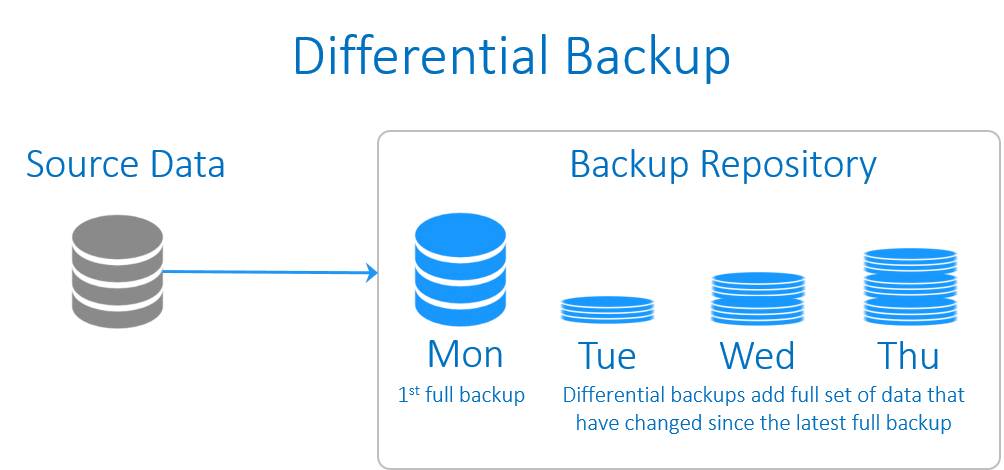
ویژگی ها
از لحاظِ سرعتِ پشتیبان گیری/بازگردانی، بکاپ differential به عنوانِ راهکاری است که در میانِ دو راهکار بکاپِ کامل و بکاپ افزایشی قرار می گیرد:
- عملیات بکاپ گیری از اطلاعات در آن کندتر از بکاپ افزایشی اما سریعتر از بکاپ کامل است
- عملیات بازگردانیِ آن، آهسته تر از بکاپ کامل اما سریع تر از بکاپ افزایشی است
فضای ذخیره سازی لازم برای بکاپِ differential، حداقل در یک دوره مشخص، کمتر از فضای لازم برای بکاپِ کامل و بیشتر از فضای مورد نیاز برای بکاپ افزایشی است.
Mirror backup
این راهکار مشابه با بکاپ گیری از اطلاعات به طور کامل است. این نوع بکاپ گیری از اطلاعات، کپی دقیقی از مجموعه داده ها ایجاد می کند با این تفاوت که بدون ردیابیِ نسخه های مختلفِ فایل ها، تنها آخرین نسخه از داده در بکاپ ذخیره می شود.
بکاپِ Mirror ، فرآیند ایجاد کپی مستقیمی از فایل ها و فولدرهای انتخاب شده، در زمانی معین است. از آنجایی که فایل ها و فولدرها بدون هیچ گونه فشرده سازی در مقصد کپی می شود، سریع ترین انواع روش های بکاپ گیری از اطلاعات است. با وجود سرعت افزایش یافته در آن، نقاط ضعفی را نیز به همراه خواهد داشت: به فضای ذخیره سازی وسیعتری نیاز دارد و نمی تواند از طریق رمز عبور محافظت شود.
در این نوع از بکاپ گیری، هنگامی که فایل های بی کاربرد حذف می شوند، از روی بکاپِ mirror نیز حذف خواهند شد. بسیاری از خدماتِ بکاپ ، بکاپِ mirror را با حداقل 30 روز فرصت برای حذف پیشنهاد می کنند. به این معناست که به هنگام حذف یک فایل از منبع، آن فایل حداقل 30 روز بر روی storage server نگهداری می شود.
ویژگی ها
امتیازی که بکاپِ mirror در اختیار شما می گذارد، بکاپی درست است که شامل فایل های منسوخ شده و قدیمی نمی شود.
و اما معایب آن زمانی خود را نشان خواهد داد که فایل ها به صورت تصادفی یا به واسطه ویروس ها از منبع حذف شده باشند.
Reverse Incremental Backup (بکاپ افزایشی معکوس)
در این نوع بکاپ گیری از اطلاعات نیز برای شروع به یک بکاپ کامل اولیه نیاز است. پس از ایجاد بکاپِ کامل اولیه، هر بکاپ افزایشیِ موفق تغییرات را به نسخه پیشین اعمال می کند که در نتیجه آن در هر زمان یک بکاپ کاملِ جدید (به صورت مصنوعی) ایجاد می شود. در حالی که کماکان توانایی بازگشت به نسخه های پیشین وجود دارد. هر یک از بکاپ های افزایشیِ اعمال شده به بکاپ کامل، نیز ذخیره می شوند که در زنجیره ای از بکاپ ها، به طور مستمر در پشت سرِ بکاپ کاملِ به روز شده، در جریان هستند.
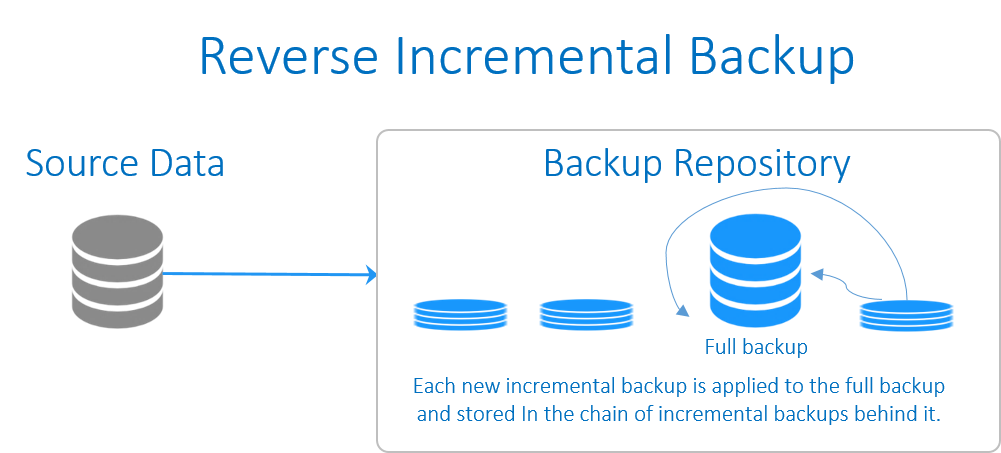
امتیاز اصلی در این نوع از بکاپ گیری فرآیند بازیابی کارآمدترِ آن است، چرا که بخش زیادی از جدیدترین نسخه های داده به بکاپ کامل اولیه اضافه می شود و نیازی ندارید بکاپ های افزایشی را در طول بازیابی بکار ببندید. در گیف زیر فرآیند اجرای این نوع بکاپ نشان داده شده است.

Smart backup (بکاپ هوشمند)
بکاپ هوشمند، ترکیبی از بکاپ های کامل، افزایشی و تفاضلی است. بسته به هدفی که در بکاپ گیری از اطلاعات در نظر دارید و همچنین فضای ذخیره سازیِ در دسترس، بکاپ هوشمند می تواند راهکاری کارآمد را ارائه دهد. جدول زیر ایده ای در رابطه با چگونگی کارکرد این نوع بکاپ، در اختیار شما می گذارد.

با استفاده از بکاپ هوشمند، همیشه می توانید تضمین نمایید که فضای ذخیره سازیِ کافی برای بکاپ های خود در اختیار دارید.
Continuous Data Protection (محافظت مستمر از داده)
بر خلاف بکاپ های دیگر که به صورت دوره ای انجام می شوند، CDP از هر تغییری در مجموعه داده های منبع log تهیه می کند که از سویی مشابه با بکاپِ mirror است. اختلاف CDP با mirror در این است که log مربوط به تغییرات برای بازیابیِ نسخه های قدیمی تر از داده می تواند بازیابی شود.
Synthetic Full Backup (بکاپ کامل ساختگی)
این نوع از بکاپ شباهت های بسیاری با بکاپ افزایشی معکوس دارد. اختلافِ آنها در چگونگی مدیریت داده هاست. بکاپ کامل مصنوعی با اجرای بکاپ کاملِ مرسوم آغاز می شود که در ادامه مجموعه ای از بکاپ ها افزایشی را در پی دارد. در زمانی معین، بکاپ های افزایشی هماهنگ می شوند و به بکاپ کاملِ موجود اعمال می شوند تا بکاپ کاملی را به طور مصنوعی و به عنوان یک نقطه شروعِ جدید ایجاد نمایند.
بکاپ کاملِ ساختگی، تمامی امتیازات یک بکاپ کامل را دارد، در حالی که زمان و فضای ذخیره سازیِ کمتری را صرف می کند.
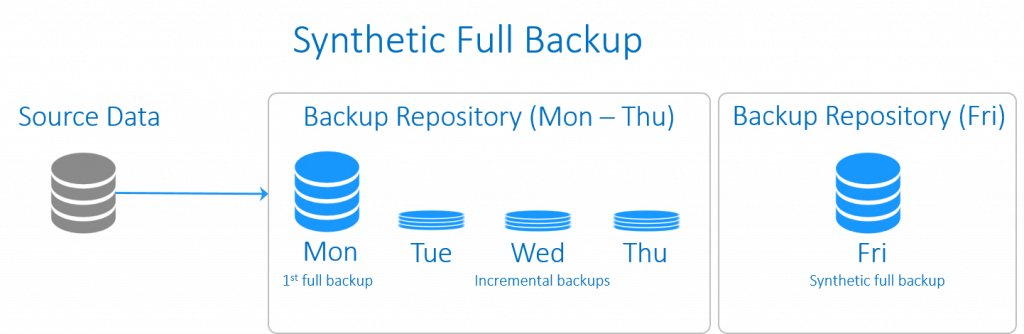
از جمله مزایای بهره وری از بکاپ کامل ساختگی عبارتند از:
- عملیات بازیابی و بکاپ گیریِ سریع
- مدیریتِ بهترِ ذخیره ساز
- نیاز کمتر به فضای ذخیره سازی
- یارهای کاریِ کمتر در شبکه
Forever-Incremental Backup
این راهکار با بکاپ افزایشی عادی متفاوت است. همچون اکثر راهکارهای پیشین برای شروع به یک بکاپ کامل اولیه به عنوان یک نقطه مرجع برای ردگیری تغییرات نیاز دارد. از آن لحظه، تنها بکاپ های افزایشی بدون هیچ گونه بکاپ کاملِ دوره ای ایجاد می شوند.
فرض کنید که شما بکاپ کامل را در روز شنبه ایجاد کردید. با شروع روز بعد، بکاپ های افزایشی به صورت روزانه ایجاد می شوند. در روز یکشنبه دو بلوک جدیدِ A و B در مجموعه داده های منبع ایجاد شده اند. در روز دوشنبه بلوک A حذف و بلوکِ جدید C بر روی منبع ایجاد شده است. در روز سه شنبه بلوک B حذف و بلوک جدید D ایجاد شده است. سیستمِ forever-incremental backup تمامیِ تغییرات روزانه را پیگیری می کند. حذف بلوک های داده تکراری تا فضای ذخیره سازی مورد نیاز برای بکاپ را کاهش دهد.
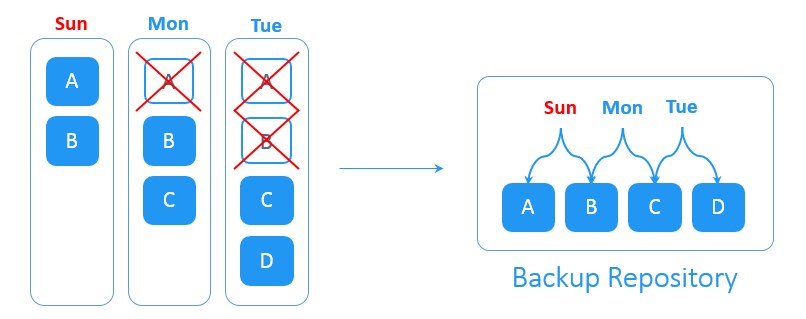
یا توجه به سیاست های ویژه در زمینه نگهداری بکاپ ها، پس از ایجادِ مجموعه ای از بکاپ های افزایشی، نقاط بکاپ گیری و بازیابیِ منقضی شده حذف می شوند تا فضای ذخیره سازیِ اشغال شده در backup repository آزاد شود.
امتیازاتی که روش بکاپ گیریِ forever-incremental نصیب شما خواهد کرد نیز مشابه با روشِ بکاپ کامل ساختگی است.
جمع بندی
در حقیقت راهکار بکاپ گیری از اطلاعات خوب یا بد وجود ندارد. باید در نظر بگیرید که چه نوعی از بکاپ گیری برای شما بهترین است و نیازهای ویژه ی سازمانِ شما را بر مبنای سیاست های محافظت از داده، ذخیره سازِ موجود، منابع، پهنای باند شبکه، نواحی داده ای مهم و …. برآورده می سازد.
توجه: برای وضوح تصاویر بر روی آن ها کلیک کنید.
منبع : http://irdatacenter.blogroz.ir/
مجازی سازی دسکتاپ
مجازی سازی دسکتاپ
امروزه بیشتر سازمان ها از محیط هایی استفاده می کنند که در آنها کامپیوتر های فیزیکی و pc ها مستقر هستند. در این محیط ها که به احتمال زیاد همه ی ما با آن آشنا هستیم، وجود pc هایی که هر کدام به طور مستقل قطعات تشکیل دهنده ی خود را دارند (مادربرد، رم، پردازنده، پاور و...) و آسیب هایی که این قطعات با آنها درگیر هستند منجر به مصرف انرژی، هزینه ی نگهداری و استهلاک بالا می شوند در حالی که فضای مدیریت مناسبی را هم ارائه نمی دهند. از طرفی در سمت کاربران تجهیزاتی وجود دارد که هر کدام از آن ها فضای فیزیکی زیادی را اشغال می کنند. اما چه راهکاری برای غلبه بر این معضلات در محیط کاری شما وجود دارد؟
مجازی سازی دسکتاپ چیست؟
یکی از کارآمدترین راهکارهای مجازی سازی، مجازی سازی دسکتاپ (VDI) می باشد. در مجازی سازی دسکتاپ به هر کلاینت یک ماشین مجازی اختصاص داده می شود که متناسب با نیاز کلاینت، منابع پردازشی لازم در اختیار ماشین قرار می گیرد و سیستم عامل بر روی آن نصب می شود. در واقع کاربران روی میز کار خود از این سیستم عامل ها استفاده می کنند، در حالی که پردازش های مربوط به آن ها روی سرور انجام می شود. به عبارتی مجازی سازی دسکتاپ جدا سازی مکان قرارگیری سیستم عامل از محیط کاربری و انتقال آن به دیتاسنتر است.
سرورها برای به کارگیری مجازی سازی دسکتاپ و ساخت ماشین های مجازی که قابلیت های دسکتاپ را به صورت مجازی ارائه می دهند، از Hypervisor استفاده می کنند.
به سناریو زیر توجه کنید:
فرض کنید سازمان شما به 150 کلاینت نیاز دارد، برای رفع این نیاز دو راه در پیش رو دارید. در رویکرد اول که روشی سنتی است، باید دیوایس هایی مانند کیس، all in one و... تهیه شود که برای این تعداد کلاینت می تواند هزینه ی خرید و پیاده سازی بالایی را به همراه داشته باشد. هزینه های نگهداری و پشتیبانی از تجهیزات و مصرف انرژی آن ها از فاکتور های مهم در محاسبه ی مخارج سازمان می باشد. از طرفی با توجه به مشکلات موجود در تامین انرژی، امروزه یکی از مهم ترین کارهایی که هر شخص باید در انجامش کوشا باشد، صرفه جویی در مصرف انرژی است اما در این رویکرد 150 دستگاه وجود دارد که هر کدام استهلاک، هزینه ی نگهداری و مصرف انرژی خود را دارند. بنابراین اتلاف انرژی زیاد و مقرون به صرفه نبودن از نتایج رویکرد اول خواهد بود. رویکرد دوم، همان راهکار مجازی سازی دسکتاپ است که به شما اجازه خواهد داد، منابع پردازشی خود را در دیتاسنتر گردآورید. اگر سازمان شما از رویکرد دوم استفاده کند، ممکن است هزینه ی پیاده سازی آن برابر با رویکرد اول یا حتی بیشتر از آن شود، اما هزینه ی نگداری کمتری را در آینده به شما تحمیل خواهد کرد. برای دستیابی به درکی بهتر از این مسئله به مثال زیر توجه کنید:
اگر سازمان شما نیازمند ارتقای منابع پردازشی کلاینتها باشد، رویکرد اول برای خرید سخت افزار و نصب آن روی کلاینت به هزینه های بیشتری نیاز دارد، در حالی که در مجازی سازی دسکتاپ، با استفاده از فضای مدیریتی که مجازی سازی در اختیارتان قرار می دهد به راحتی می توانید منابع پردازشی و ذخیره سازی یک کلاینت را ارتقا دهید. با استفاده از مجازی سازی دسکتاپ شما می توانید در مصرف انرژی صرفه جویی کنید، هزینه های نگهداری را کاهش دهید، امنیت بیشتر، مدیریت بهتر و بهینه تری را روی سیستم هایتان داشته باشید.
توجه کنید که مجازی سازی دسکتاپ (bare metal) را با نوعی مجازی سازی که توسط نرم افزار هایی مانند VMware Workstation و Virtual Box در دسکتاپ انجام می شود، اشتباه نگیرید.

مزایای مجازی سازی دسکتاپ
مجازی سازی دسکتاپ مزایای زیادی برای فناوری اطلاعات و سازمان ها دارد. برخی از مهم ترین آن ها عبارت اند از:
- صرفه جویی در هزینه ها : از منظر فناوری اطلاعات، مجازی سازی دسکتاپ هزینه های مدیریت و پشتیبانی و زمان ایجاد یک دسکتاپ جدید را کاهش می دهد. کارشناسان معتقدند که نگهداری و مدیریت منابع در محیط مجازی سازی شده 50 تا 70 درصد از مجموع هزینه مالکیت (TCO) یک محیط فیزیکی را دربر می گیرد. سازمان ها معمولا برای صرفه جویی در این هزینه ها به مجازی سازی دسکتاپ روی می آورند.
- سهولت مدیریت : از آنجایی که در مجازی سازی همه چیز به صورت مرکزی مدیریت، ذخیره و محافظت می شود، مجازی سازی دسکتاپ نیاز به نصب، به روز رسانی، patch کردن برنامه ها، بک آپ گرفتن از اطلاعات و شناسایی ویروس ها در کلاینت های مختلف را از بین می برد. بنابراین مجازی سازی دسکتاپ به ساده سازی مدیریت برنامه های موجود کمک می کند. در مجازی سازی دسکتاپ می توان از کلاینت های قدیمی به عنوان ایستگاه های دریافت کننده سرویس دسکتاپ مجازی (Thin client) استفاده کرد. برخلاف کامپیوتر های شخصی که توان پردازشی، فضای ذخیره سازی و حافظه ی رم مورد نیاز برای اجرای برنامه ها را در داخل خود دارند، thin client ها به عنوان دسکتاپ های مجازی عمل می کنند و در بستر شبکه از توان پردازشی سرور موجود در شبکه بهره می برند.
- امنیت بیشتر : مدیریت بهینه ی موجود در دسکتاپ های مجازی، امکان اتصال دستگاه های ذخیره ساز قابل حمل به سیستم های thin client را نمی دهد مگر اینکه دسترسی این عملکرد به کاربران داده شود. به همین خاطر امکان درز اطلاعات، نفوذ بد افزار ها و باج افزار ها به این سیستم ها کاهش پیدا می کند. مطلب دیگری که امنیت محیط مجازی سازی شده را افزایش می دهد این است که تمامی اطلاعات سازمان حتی اطلاعاتی که کاربران در پروفایل خود ذخیره می کنند در دیتاسنتر ذخیره و نگهداری می شود و از آنجایی که داده های کاربر به صورت مرکزی و منظم پشتیبان گیری می شود، مجازی سازی دسکتاپ مزایای یکپارچگی داده را نیز فراهم می کند.
- بهره وری بیشتر : مجازی سازی دسکتاپ به کابران این امکان را می دهد که از طریق دستگاه های مختلف مانند دسکتاپ های دیگر، لپتاپ ها، تبلت ها و گوشی های هوشمند به برنامه ها و اطلاعات مورد نیاز دسترسی داشته باشند. این امر بهره وری را با ارائه اطلاعات مورد نیاز به کاربران در هر مکانی، افزایش می دهد. از طرفی اگر دستگاه یکی از کاربران آسیب دید از آنجایی که اطلاعات دسکتاپ به صورت locally ذخیره نمی شود، آن کاربر می تواند از دستگاه های دیگر برای دسترسی به دسکتاپ و رسیدگی به ادامه کارش استفاده کند.
منبع : Faradsys.com
مقایسه ipv4 با ipv6
مقایسه ipv4 با ipv6
آدرس IP شناسه ای یکتا برای مشخص شدن یک device در یک شبکه می باشد. یکتا بودن آدرس IP بدین معناست که آدرس IP یک device داخل شبکه ای که در آن قرار دارد فقط به آن سیستم اختصاص دارد . تا زمانی که یک device آدرس IP نداشته باشد نمی تواند با device های دیگر ارتباط برقرار کند .
آدرس های IP به دو دسته تقسیم می شوند . دسته ی اول IPv4 می باشد که اکثر ما با آن برخورد داشته ایم و تا حدودی با آن آشنا هستیم. آدرس IP ورژن 4 یک آدرس 32 بیتی است که به صورت 4 عدد در مبنای ده که با نقطه از هم جدا شده اند، نمایش داده می شود (مانند : 192.168.1.1 ). این ورژن از IP به تعداد 2 به توان 32 آدرس را ارائه می کند. در حال حاضر بیش از 90 درصد آدرس ها در جهان ، IPv4 می باشد.
از آنجایی که استفاده از پروتکل TCP/IP در سال های اخیر بیش از حد انتظار بوده، در آدرس دهی IPv4 ، محدود هستیم و آدرس های IPv4 رو به اتمام است. این یکی از دلایلی است که TCP/IP یک ورژن جدید از آدرس های IP را طراحی کرد که با نام IPv6 شناخته می شود.
بعضی از مزیت هایی که IPv6 دارد :
- هزینه ی کمتر پردازشی : packet های IPv6 باز طراحی شده اند تا header های ساده تری را تولید و استفاده کنند که این موضوع فرایند پردازش packet ها توسط سیستم های فرستنده و گیرنده را بهبود می دهد.
- آدرس های IP بیشتر : IPv6 از ساختار آدرس دهی 128 بیتی استفاده می کند در حالی که IPv4 از ساختار آدرس دهی 32 بیتی استفاده می کند . این تعداد آدرس IP این اطمینان را می دهد که حتی بیشتر از آدرس های مورد نیاز در سال های آینده ، آدرس موجود است.
- Multicasting : در IPv6 از Multicasting به عنوان روش اصلی برقرار کردن ارتباط استفاده می شود. IPv6 بر خلاف IPv4 روش broadcast را ارائه نمی دهد. روش broadcast از پهنای باند شبکه به صورت غیر بهینه و نامناسب استفاده می کند.
- IPSec: پروتکل Internet Protocol Security)IPSec) در درون IPv4 وجود نداشت اما IPv4 از آن پشتیبانی می کرد در حالی که IPv6 این پروتکل را به صورت built in در درون خود دارد و می تواند تمامی ارتباطات را رمز گذاری (encrypt) کند.
آدرس دهی در IPv6
در IPv6 تغییرات عمده ای نسبت به IPv4 وجود دارد. IPv4 از ساختار آدرس دهی 32 بیتی استفاده می کند در حالی که IPv6 از ساختار آدرس دهی 128 بیتی استفاده می کند. این تغییر می تواند 2 به توان 128 آدرس یکتا را ارائه دهد . این میزان آدرس IP، پیشرفت بسیار زیادی را نسبت به تعداد آدرس IP که IPv4 ارائه می کند(2 به توان 32) دارد.
آدرس IPv6 دیگر از 4 بخش 8 بیتی استفاده نمی کند. آدرس IPv6 به 8 قسمت 16 بیتی که هر قسمت ارقامی در مبنای 16 هستند و با (:) از هم جدا می شوند تقسیم میشود. مانند:
65b3:b834:45a3:0000:0000:762e:0270:5224
در مورد آدرس های IPv6 یک سری نکته هایی وجود دارد که باید آنها را بدانید:
- این آدرس ها نسبت به بزگی حروف حساس نیستند
- صفر های سمت چپ هر بخش را میتوان حذف کرد
- بخش هایی که پشت سر هم صفر هستند را میتوان به صورت (::) خلاصه نویسی کرد (روی هر آدرس فقط یک بار می توان این کار را کرد)
مثال: آدرس loopback در IPv6 به صورت زیر است :
0000:0000:0000:0000:0000:0000:0000:0001
از آنجایی که می توان صفرهای سمت چپ هر بخش را حذف کرد آدرس را بازنویسی می کنیم :
0:0:0:0:0:0:0:1
بعد از حذف کردن صفرهای سمت چپ ، می توانیم صفرهای پشت سر هم را نیز خلاصه نویسی کنیم :
1::
همانطور که اشاره کردیم ، فقط یک بار می توانیم صفرهای پشت سر هم را خلاصه نویسی کنیم ، علت این موضوع این است که اگر چند بار این خلاصه نویسی را روی بخش های مختلف آدرس انجام دهیم ، آدرس اصلی بعد از خلاصه نویسی مشخص نخواهد بود . به مثال زیر توجه کنید:
0000:0000:45a3:0000:0000:0000:0270:5224
در این مثال دو سری صفر های پشت سر هم وجود دارد . اگر هر دو را خلاصه نویسی کنیم به صورت زیر می شود :
45a3::270:5224::
در این حالت مشخص نیست که هر سری چه تعداد صفر پشت سر هم داشته ایم ، پس بهتر است که آن سری که تعداد صفر های بیشتری پشت سر هم دارد را خلاصه نویسی کنید.
0:0:45a3::270:5224
ساختار آدرس دهی در IPv6 به کلی تغییر کرده است ، به طوری که 3 نوع آدرس وجود دارد :
- Unicast: آدرس Unicast برای ارتباطات یک به یک استفاده می شود.
- Multicast: آدرس Multicast برای ارسال data به سیستم های مختلف در یک لحظه استفاده می شود. آدرس های Multicast با پیشوند FF01 شروع می شوند. برای مثال FF01::1 برای ارسال اطلاعات به تمام node ها در شبکه استفاده می شود ، در حالی که FF01::2 برای ارسال اطلاعات به تمام روترهای داخل شبکه استفاده می شود.
- Anycast: آدرس Anycast برای گروهی از سیستم ها که سرویسی را ارائه می کنند استفاده می شود.
توجه کنید که آدرس broadcast در IPv6 وجود ندارد.
آدرس های Unicast خود به سه دسته تقسیم می شود :
- Global unicast: آدرس های Global unicast ، آدرس های public در IPv6 میباشد و قابلیت مسیریابی در اینترنت دارد. این آدرس ها معادل آدرس های public در IPv4 می باشد.
- Site-local unicast: آدرس های Site-local unicast ، آدرس های private هستند و مشابه آدرس های private در IPv4 می باشند و فقط برای ارتباطات داخل شبکه ای استفاده می شوند. این آدرس ها همیشه با پیشوند FEC0 شروع می شوند.
- Link-local unicast: آدرس های Link-local unicast مشابه APIPA در IPv4 هستند و فقط می توانند برای ارتباط با سیستمی که به آن متصل هستند ، استفاده شوند. این آدرس ها با پیشوند FE80 شروع می شود.
نکته دیگری که باید به آن اشاره کنیم ، IPv6 ازClassless Inter-Domain Routing (CIDR) که در سال های اخیر متداول شده اند( برای تغییر بخش net ID روی IPv4 )،استفاده می کند.برای مثال آدرس 2001:0db8:a385::1/48 بدین معناست که 48 بیت اول آدرس تشکیل دهنده ی net ID است.
IPv6 به 3 بخش تقسیم می شود:
- Network ID: معمولا 48 بیت اول آدرس تشکیل دهنده ی net ID آن می باشد. در آدرس های global address ، net ID توسط ISP به سازمان شما اختصاص داده می شود.
- Subnet ID: این بخش از 16 بیت تشکیل شده و با استفاده از آنها می توانید شبکه ی IPv6 خود را به subnet های مختلف تقسیم کنید. برای مثال شبکه ای با net ID 2001:ab34:cd56 /48 می تواند به دو زیرشبکه 2001:ab34:cd56:0001/64 و 2001:ab34:cd56:0002/64 تقسیم شود.
- (Unique Identifier(EUI-64: نیمه ی دوم آدرس (64 بیت آخر) را unique identifier می نامند، این بخش مشابه host ID در IPv4 است (یک سیستم را در شبکه مشخص می کند). این بخش تشکیل می شود از مک آدرس آن سیستم (48 بیت)که به دو قسمت تقسیم شده و عبارت FFFE که میان آن دو قسمت قرار می گیرد.
Auto configuration
یکی از مزیت های IPv6 قابلیت auto configuration است ، که در آن سیستم یک آدرس IPv6 برای خود انتخاب می کند ، سپس با ارسال پیام neighbor solicitation به آن آدرس بررسی میکند که این آدرس در شبکه برای سیستم دیگری استفاده نشده باشد. اگر این آدرس توسط سیستم دیگری استفاده شده باشد ، به پیام جواب می دهد و سیستمی که قصد انتخاب آدرس را داشت متوجه می شود که از آن آدرس نمی تواند استفاده کند. قابل ذکر است احتمال اینکه یک آدرس به دو سیستم اختصاص داده شود خیلی کم است چون مک آدرس سیستم ها در آدرس دهی auto configuration استفاده می شود (مک آدرس یک آدرس یکتا است).
با توجه به تکنولوژی های پیش روی دنیای اطلاعات به ویژه IOT یا اینترنت اشیاء که به واسطه آن میتوان تعداد زیادی از اشیاء که در طول روز با آن ها سر و کار داریم (مانند سیستم های گرمایشی و سرمایشی، لوازم خانگی، ملزومات اداری و …)، که به صورت هوشمند کنترل می شوند را با یکدیگر در بستر اینترنت ارتباط خواهند داشت. این امر بدین معناست که به میلیاردها آدرس IP نیاز خواهیم داشت و ملزم به استفاده از IPv6 می باشیم .
نحوه کارکرد پروتکل STP
Spanning Tree Protocol
سوئیچ های سیسکو با استفاده از پروتکل STP، از به وجود آمدن loop در شبکه جلوگیری می کنند. در یک LAN که دارای مسیر های redundant می باشد، اگر پروتکل STP فعال نباشد، باعث به وجود آمدن یک loop نامحدود در شبکه می شود. اگر در همان LAN پروتکل STP را فعال کنید، سوئیچ ها برخی از پورت ها را بلاک می کنند و اجازه نمی دهند اطلاعات از آن پورت ها عبور کنند.
پروتکل STP با توجه به دو معیار پورت ها را برای بلاک کردن انتخاب می کند:
• تمامی deviceهای موجود در LAN بتوانند با هم ارتباط برقرار کنند. درواقع STP تعداد پورت های کمی را بلاک می کند تا LAN به چند بخش که نمی توانند با هم ارتباط برقرار کنند، تقسیم نشود.
• Frame ها بعد از مدتی drop می شوند و به طور نامحدود در loop قرار نمی گیرند.
پروتکل STP تعادلی را در شبکه به وجود می آورد بطوریکه frame ها به هر کدام از device ها که لازم باشد می رسند بدون اینکه مشکلات loop به وجود آید.
پروتکل STP با چک کردن هر interface قبل از اینکه از طریق آن اطلاعات ارسال کند، از به وجود آمدن loop جلوگیری می کند. در این روند چک کردن اگر آن پورت داخل VLAN خود در وضعیت STP forwarding باشد، از آن پورت در حالت عادی استفاده می کند، اما اگر در وضعیت STP blocking باشد، ترافیک تمام کاربران را بلاک می کند و هیچ ترافیکی در آن VLAN را از آن پورت عبور نمی دهد.
توجه کنید که وضعیت STP یک پورت، اطلاعات دیگر مربوط به پورت را تغییر نمی دهد. برای مثال با تغییر وضعیت خود تغییری در وضعیت trunk/access و connected/notconnect ایجاد نمی کند. وضعیت STP یک مقدار جدا از وضعیت های قبلی دارد و اگر در حالت بلاک باشد پورت را از پایه غیر فعال می کند.
نیاز به پروتکل STP
پروتکل STP از وقوع سه مشکل رایج در LANهای Ethernet جلوگیری می کند. در نبود پروتکل STP ، بعضی از frame های Ethernet برای مدت زیادی (ساعت ها، روز ها و حتی برای همیشه اگر deviceهای LAN و لینک ها از کار نیوفتند) در یک loop داخل شبکه قرار می گیرند. سوئیچ های سیسکو به طور پیش فرض پروتکل STP را اجرا می کنند. توصیه می کنیم پروتکل STP را تا زمانی که تسلط کامل به آن ندارید، غیر فعال نکنید.
اگر یک frame درloop قرار بگیرد Broadcast storm به وجود می آید. Broadcast storm زمانی به وجود می آید که هر نوعی از frameهای Ethernet (مانند multicast frame،broadcast frame و unicast frameهایی که مقصدشان مشخص نیست) در loop بی نهایت داخل LAN قرار بگیرند. Broadcast stormها می توانند لینک های شبکه را با کپی های به وجود آمده از یک frame اشباع کنند و باعث از بین رفتن frameهای مفید شوند، و نیز با توجه به بار پردازشی مورد نیاز برای پردازش broadcast frameها، تاثیر قابل ملاحظه ای روی عملکرد deviceهای کاربران دارند.
تصویر 1-2 یک مثال ساده از Broadcast storm را نشان می دهد که در آن سیستمی که Bob نام دارد یک broadcast frame ارسال می کند. خط چین ها نحوه ارسال frameها توسط سوئیچ ها را در نبود STP نمایش می دهند.
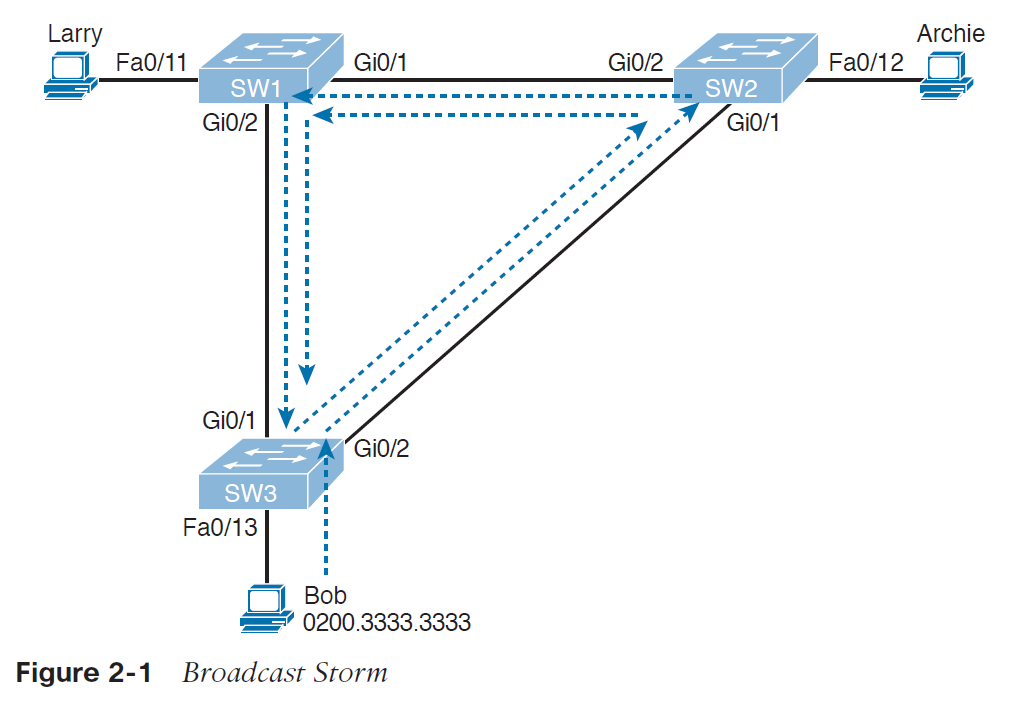
در تصویر 1-2، frameها در جهت های مختلفی می چرخند، برای ساده تر شدن مثال فقط در یک جهت آنها را نمایش داده ایم.
در مفاهیم سوئیچ، سوئیچ ها در ارسال کردن broadcast farmeها، frameها را به تمام پورت ها به جز پورت فرستنده آن frame، ارسال می کنند. در تصویر 1-2، سوئیچ SW3، frame را به سوئیچ SW2 ارسال می کند، سوئیچ SW2 آن را برای سوئیچ SW1 ارسال می کند، سوئیچ SW1 نیز آن را برای SW3 ارسال می کند و به همین ترتیب این frame به سوئیچ SW2 ارسال می شود و داخل یک loop می چرخد.
زمانی که یک Broadcast storm اتفاق می افتد، frame ها مانند مثال بالا به چرخیدن ادامه می دهند تا زمانی که تغییراتی به وجود آید (شخصی یکی از پورت ها را خاموش کند، سوئیچ را reload کند یا کاری کند که loop از بین برود).
Broadcast storm همچنین باعث به وجود آمدن مشکل نا محسوسی به نام MAC table instability یا ناپیوستگی جدول مک می شود. MAC table instability بدین معنا است که جدول مک آدرس پیوسته در حال تغییر کردن می باشد، و علت آن این است کهframe هایی با مک آدرس یکسان از پورت های مختلفی وارد سوئیچ ها می شوند. به مثال زیر توجه کنید:
در تصویر 1-2 در ابتدا سوئیچ SW3 مک آدرس باب را که از طریق پورت Fa0/13 وارد سوئیچ شده، به جدول مک آدرس خود اضافه می کند:
0200.3333.3333 Fa0/13 VLAN 1
حالا فرایند switch learning را در نظر بگیرید در زمانی که frame در حال چرخش از سوئیچSW3 به سوئیچ SW2 ، سپس به سوئیچ SW1 و بعد از آن از طریق پورت G0/1 وارد سوئیچ SW3 می شود. سوئیچ SW3 می بیند که مک آدرس مبداء 0200.3333.3333 می باشد و از پورت G0/1 وارد سوئیچ شده است، جدول مک آدرس خود را به روز می کند:
0200.3333.3333 G0/1 VLAN 1
در این مورد سوئیچ SW3 هم دیگر نمی تواند به درستی frameها را به مک آدرس باب برساند. اگر در این حالت یک frame (خارج از frameهایی که در داخل loop افتاده اند) به سوئیچ SW3 برسد که مقصد آن باب باشد، سوئیچ SW3 اشتباها frame را روی پورت G0/1 به سوئیچ SW1 ارسال می کند، که این موضوع ترافیک زیادی را به وجود می آورد.
سومین مشکلی که Frame های در حال چرخش در یک broadcast storm ایجاد می کنند این است که کپی های مختلفی از یک frame به دست گیرنده می رسد. در تصویر 1-2 فرض کنید که باب یک frame را برای لاری ارسال کند در حالی که هیچ کدام از سوئیچ ها مک آدرس لاری را نمی دانند. سوئیچ ها frameها را به صورت unicast هایی که مک آدرس مقصدشان مشخص نیست، ارسال می کنند. زمانی که باب یک frame که مک آدرس مقصدش لاری است را ارسال می کند، سوئیچSW3 یک کپی از آن را به سوئیچ های SW1 و SW2 ارسال می کند. سوئیچ های SW1 و SW2 نیز frame را broadcast می کنند، این کپی ها باعث می شود که آن frame در داخل یک loop قرار گیرد. سوئیچ SW1 همچنین یک کپی از frame را به پورت Fa0/11 برای لاری ارسال می کند. در نتیجه لاری کپی های مختلفی از آن frame را دریافت می کند، که می تواند باعث از کار افتادن برنامه ای در سیستم لاری و یا مشکلات شبکه ای شود.
جدول زیر خلاصه ای از سه مشکل اساسی در شبکه ای که دارای redundancy است و STP در آن اجرا نمی شود را نشان می دهد:
پروتکل (STP (IEEE 802.1D دقیقا چه کار می کند؟
پروتکلSTP با قرار دادن هر یک از پورت های سوئیچ در وضعیت های forwarding و blocking از به وجود آمدن loop جلوگیری می کند. پورت هایی که در وضعیت forwarding هستند به صورت عادی فعالیت می کنند، frameها را ارسال و دریافت می کنند. اما پورت هایی که در وضعیت blocking قرار دارند به جز پیام های مربوط به پروتکل STP (و برخی دیگر از پیام هایی که برای پروتکل ها استفاده می شوند) ، هیچ frame دیگری را پردازش نمی کنند. این پورت ها frameهای کاربران را ارسال نمی کنند، مک آدرس frameهای ورودی را ذخیره نمی کنند و frameهای دریافتی از کاربران را نیز پردازش نمی کنند.
تصویر 2-2 راه حل استفاده از پروتکل STP (قرار دادن یکی از پورت های سوئیچ SW3 در وضعیت blocking) در مثال پیشین را نمایش می دهد:
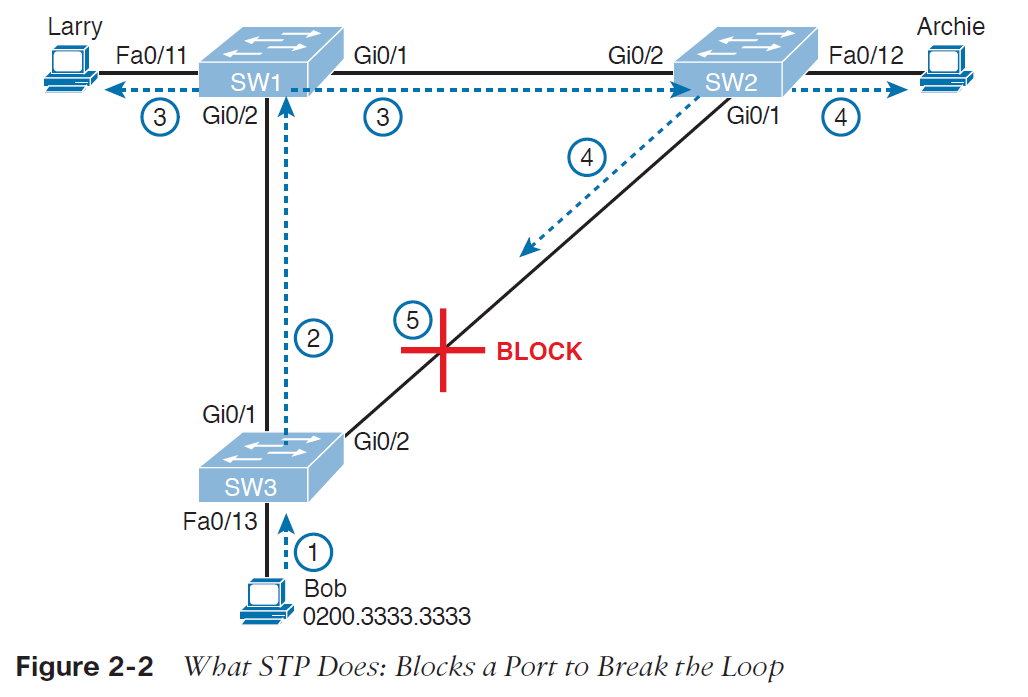
همانطور که در مراحل زیر نشان داده شده، زمانی که باب یک broadcast را ارسال می کند، دیگر loop به وجود نمی آید:
• مرحله اول: باب frame را به سوئیچ SW3 ارسال می کند.
• مرحله دوم: سوئیچ SW3 این frame را فقط به سوئیچ SW1 ارسال می کند، دیگر به سوئیچ SW2 ارسال نمی شود چون پورت G0/2 در وضعیت blocking قرار دارد.
• مرحله سوم: سوئیچ SW1 این frame را روی پورت های Fa0/12 و G0/1 ارسال می کند.
• مرحله چهارم: سوئیچ SW2 این frame را روی پورت های Fa0/12 و G0/1 ارسال می کند.
• مرحله پنجم: سوئیچ SW3 به صورت فیزیکی یک frame را دریافت می کند، اما frame دریافتی از SW2 را به دلیل اینکه پورت G0/2 در سوئیچ SW3 در وضعیت blocking قرار دارد، نادیده می گیرد.
با استفاده از توپولوژی STP در تصویر 2-2، سوئیچ ها از لینک موجود بین SW2 و SW3 برای انتقال ترافیک استفاده نمی کنند. با این حال، اگر لینک بین SW3 و SW1 دچار مشکل شود، پروتکل STP پورت G0/2 را از وضعیت blocking به وضعیت forwarding تغییر می دهد و سوئیچ ها می توانند از آن لینکredundant استفاده کنند. در این موقعیت ها پروتکل STP با انجام فرایند هایی متوجه تغییرات در توپولوژی شبکه می شود و تشخیص می دهد که پورت ها نیاز به تغییر در وضعیتشان دارند و وضعیت آن ها را تغییر می دهد.
سوالاتی که احتمالا زهن شما را نیز مشغول کرده: پروتکل STP چگونه پورت ها را برای تغییر وضعیت انتخاب می کند و چرا این کار را می کند؟ چگونه وضعیت blocking را برای بهره مندی از مزایای لینک های redundant، به وضعیت forwarding تغییر می دهد؟ در ادامه به این سوالات پاسخ خواهیم داد.
پروتکل STP چگونه کار می کند؟
الگوریتم STP یک درخت پوشا (spanning tree) از پورت هایی که frameها را ارسال می کنند تشکیل می دهد. این ساختار درختی، مسیرهایی را برای رسیدن لینک های ethernet به هم مشخص می کند. (مانند پیمودن یک درخت واقعی که از ریشه درخت شروع می شود و تا برگ ها ادامه دارد)
توجه: STP قبل از اینکه در سوئیچ های LAN استفاده شود، در Ethernet bridgeها به کار رفته بود.
STP از فرایندی که بعضا spanning-tree algorithm)STA) نامیده می شود، استفاده می کند که در آن پورت هایی که باید در وضعیت forwarding قرار بگیرند را انتخاب می کند. STP پورت هایی که برای forwarding انتخاب نشدند را در وضعیت blocking قرار می دهد. در واقع پروتکل STP پورت هایی که در ارسال کردن اطلاعات باید فعال باشند را انتخاب می کند و پورت های باقی مانده را در وضعیت blocking قرار می دهد.
پروتکل STP برای قرار دادن پورت ها در حالت forwarding از سه مرحله استفاده می کند:
• پروتکل STP یک سوئیچ را به عنوان root انتخاب می کند و تمام پورت های فعال در آن سوئیچ را در وضعیت forwarding قرار می دهد.
• در هر کدام از سوئیچ های nonroot (همه ی سوئیچ ها به جز root)، پورتی که کمترین هزینه را برای رسیدن به سوئیچ root دارد (root cost)، به عنوان root port(RP) انتخاب می کند و آن ها را در وضعیت forwarding قرار می دهد.
• تعداد زیادی سوئیچ می توانند به یک بخش از Ethernet متصل شوند، اما در شبکه های مدرن، معمولا دو سوئیچ به هر لینک (بخش) متصل می شوند. در بین سوئیچ هایی که به یک لینک مشترک متصل هستند، پورت سوئیچی که root cost کمتری دارد در وضعیت forwarding قرار می گیرد. این سوئیچ ها را designated switch می نامند و پورت هایی که در وضعیت forwarding قرار گرفته را designated port)DP) می نامند.
باقی پورت ها در وضعیت blocking قرار می گیرند.
خلاصه ای از علت قرار گرفتن پورت ها در وضعیت های blocking و forwarding توسط پورتکل STP
Bridge و Hello BPDU
فرایند STA با انتخاب یک سوئیچ به عنوان root شروع می شود. برای اینکه روند انتخاب را بهتر متوجه شوید، شما باید با مفهوم پیام هایی که بین سوئیچ ها تبادل می شود به خوبی آشنا شوید و با فرمت شناساگری که برای شناسایی هر سوئیچ استفاده می شود آشنا باشید.
(STP bridge ID (BID یک مقدار 8 بایتی برای شناسایی هر سوئیچ می باشد. Bridge ID به دو بخش 2 بایتی که مشخص کننده اولویت و حق تقدم است و 6 بایتی که system ID نامیده می شود و همان مک آدرس هر سوئیچ است، تقسیم می شود. استفاده از مک آدرس این اطمینان را می دهد که bridge ID هر سوئیچ یکتا خواهد بود.
پیام هایی که برای تبادل اطلاعات مربوط به پروتکل STP بین سوئیچ ها استفاده می شود، bridge protocol data units )BPDU) نام دارد. رایج ترین BPDU ، که hello BPDU نام دارد، تعدادی از اطلاعات که شامل BID سوئیچ ها نیز می شود را لیست می کند و ارسال می کند. با استفاده از BID درج شده روی هر پیام، سوئیچ ها می توانند تشخیص دهند که هر پیام Hello BPDU از طرف کدام سوئیچ است.
جدول زیر اطلاعات کلیدی مربوط به Hello BPDU را نشان می دهد:
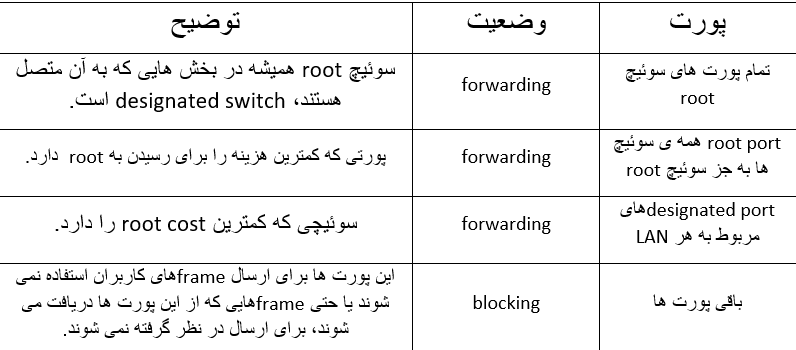
انتخاب سوئیچ root
سوئیچ ها با استفاده از BIDهای موجود در پیام های BPDU، سوئیچ root را انتخاب می کنند. سوئیچی که عدد BID آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب می شود. با توجه به اینکه بخش اول عدد BID مقدار اولویت می باشد، سوئیچی که مقدار اولویت پایین تری داشته باشد به عنوان سوئیچ root انتخاب می شود. برای مثال اگر سوئیچ های اول و دوم به ترتیب دارای اولویت های 4096 و 8192 باشند، بدون در نظر گرفتن مک آدرس سوئیچ ها که در به وجود آمدن BID هر سوئیچ موثر است، سوئیچ اول به عنوان سوئیچ root انتخاب خواهد شد.
اگر مقدار اولویت دو سوئیچ برابر شد، سوئیچی که مک آدرس آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب می شود. در این حالت به علت یکتا بودن مک آدرس، حتما یک سوئیچ انتخاب خواهد شد. پس اگر مقدار اولویت دو سوئیچ برابر باشد و مک آدرس آنها 0200.0000.0000 و 0911.1111.1111 باشد، سوئیچی که دارای مک آدرس 0200.0000.0000 است، به عنوان سوئیچ root انتخاب می شود.
مقدار اولویت مضربی از 4096 است و به صورت پیش فرض برای همه ی سوئیچ ها مقدار 32768 را دارد. از آنجایی که مک آدرس سوئیچ ها معیار مناسبی برای انتخاب سوئیچ root نمی باشد بهتر است به صورت دستی مقدار اولویت را تغییر دهیم تا سوئیچی که می خواهیم به عنوان سوئیچ root انتخاب شود.
در فرایند انتخاب سوئیچ root، سوئیچ ها از طریق فرستادن پیام های Hello BPDU که BID خود را در این پیام ها به عنوان root BID قرار داده اند، سعی می کنند خود را به عنوان سوئیچ root به سوئیچ های مجاور خود معرفی کنند. اگر یک سوئیچ پیامی را دریافت کند که BID کمتری نسبت به BID خودش داشته باشد، آن سوئیچ دیگر خود را به عنوان سوئیچ root معرفی نمی کند، به جای آن شروع به ارسال پیام دریافتی که دارای BID بهتری است می کند (مانند رقابت های انتخاباتی که یک نامزد به نفع نامزد هم حزبش که موقعیت بهتری دارد، از رقابت در انتخابات خارج می شود). در نهایت تمامی سوئیچ ها به یک نظر نهایی می رسند که کدام سوئیچ BID کمتری دارد و همه آن سوئیچ را به عنوان سوئیچ root انتخاب می کنند.
توجه : در مقایسه دو پیام Hello با هم، پیامی که BID کمتری دارد، superior Hello و پیامی که BID بیشتری دارد، inferior Hello نام دارد.
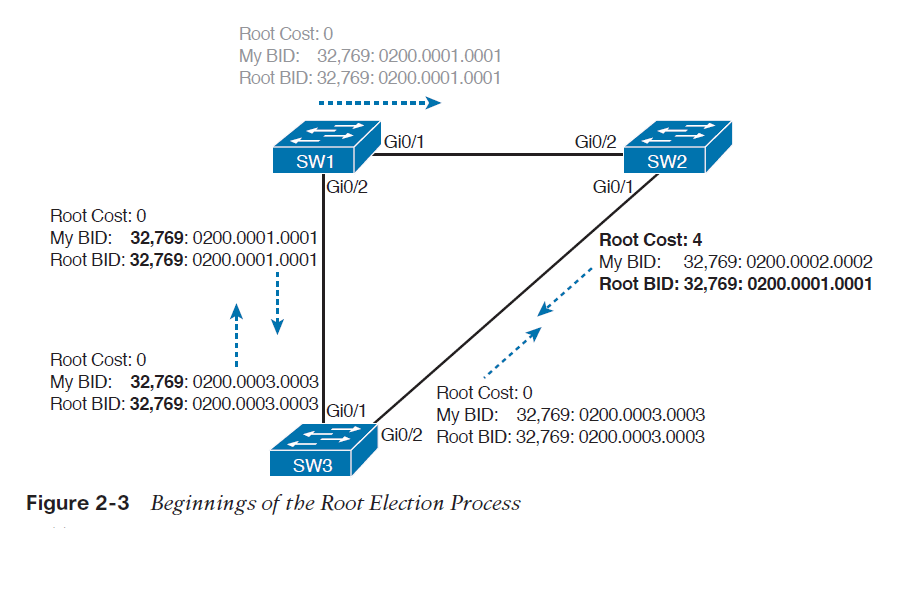
تصویر 3-2 آغاز فرایند انتخاب سوئیچ root را نشان می دهد، در ابتدای این فرایند SW1 همانند باقی سوئیچ ها خود را به عنوان سوئیچ root معرفی می کند. SW2 پس از دریافت Hello مربوط به SW1 متوجه می شود که SW1 شرایط بهتری را برای root بودن دارد، پس شروع به ارسال Hello دریافتی از SW1 می کند. در این حالت سوئیچ SW1 خود را به عنوان root معرفی می کند و SW2 نیز با آن موافقت می کند اما سوئیچ SW3 هنوز سعی می کند که خود را به عنوان سوئیچ root معرفی کند و Hello BPDUهای خود را ارسال می کند.
دو نامزد هنوز باقی ماندند:SW1 و SW3. از آنجایی که SW1 مقدار BID کمتری دارد، SW3 پس از دریافت BPDU مربوط به SW1، SW1 را به عنوان سوئیچ root می پذیرد و به جای BPDU خود، BPDU دریافتی از SW1 را به سوئیچ های مجاور ارسال می کند.
پس از اینکه فرایند انتخاب تکمیل شد، فقط سوئیچ root به تولید پیام های Hello BPDU ادامه می دهد. سوئیچ های دیگر این پیام ها را دریافت می کنند و BID فرستنده و root costرا تغییر می دهند و به باقی پورت ها ارسال می کنند. در تصویر 4-2، در قدم اول سوئیچ SW1 پیام های Hello را ارسال می کند، در قدم دوم سوئیچ های SW2 و SW3 به صورت مستقل تغییرات را روی پیام های دریافتی اعمال می کنند و آن ها را روی پورت های خود ارسال می کنند.
برای اینکه بخواهیم مقایسه BID را خلاصه کنیم، BID را به بخش های تشکیل دهنده ان تقسیم می کنیم، سپس به صورت زیر مقایسه می کنیم:
• اولویتی که کمترین مقدار را دارد
• اگر مقدار اولویت آن ها برابر باشد، سوئیچی که مک ادرسش کمترین مقدار را دارد
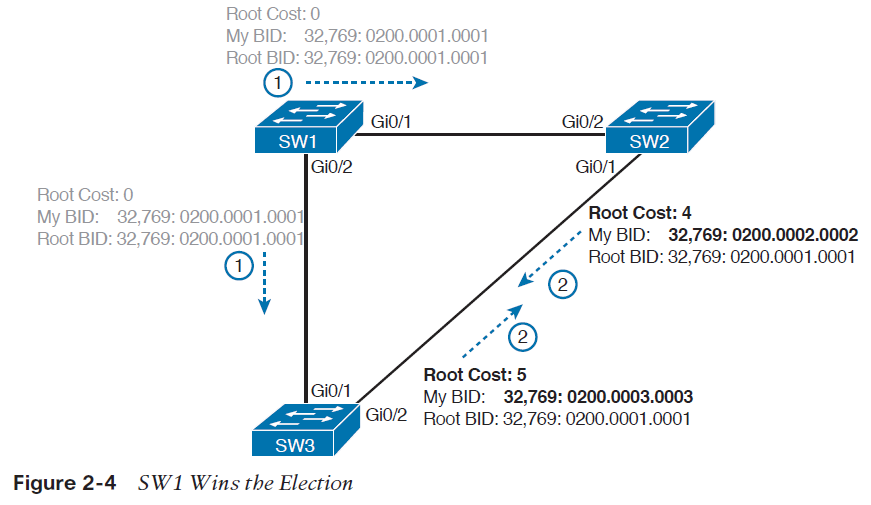
انتخاب Root Port برای هر سوئیچ
در مرحله ی بعدی، پس از انتخاب سوئیچ root، پروتکل STP برای سوئیچ های nonroot (همه ی سوئیچ ها به جز سوئیچ root) یک root port )RP) انتخاب می کند. RP هر سوئیچ، پورتی است که کمترین هزینه را برای رسیدن به سوئیچ root دارد.
احتمالا عبارت هزینه برای همه ی ما در انتخاب مسیر بهتر، روشن و مشخص باشد. اگر به دیاگرام شبکه ای که در آن سوئیچ root و هزینه ارسال اطلاعات روی هر پورت مشخص باشد توجه کنید، می توانید هزینه برقراری ارتباط با سوئیچ root را برای هر پورت به دست آورید. توجه کنید که سوئیچ ها برای به دست آوردن هزینه برقراری ارتباط با سوئیچ root، از دیاگرام شبکه استفاده نمی کنند، صرفا استفاده از آن برای درک این موضوع به ما کمک می کند.
تصویر 5-2 همان سوئیچ های مثال پیشین که در آن سوئیچ root و هزینه ی رسیدن به سوئیچ root را برای پورت های سوئیچ SW3 نشان می دهد.
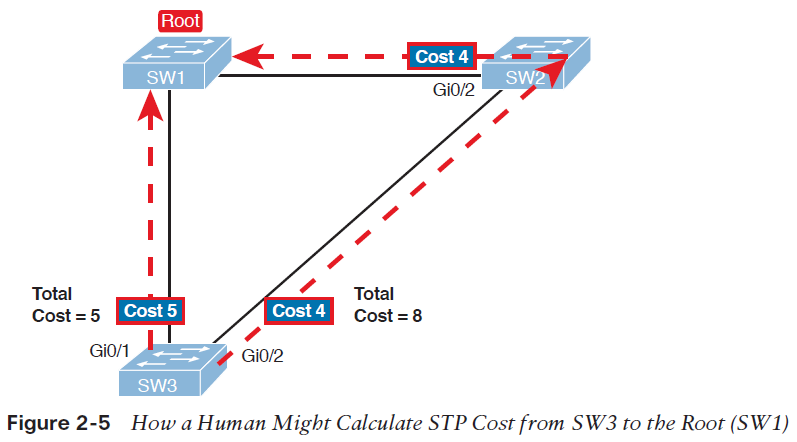
سوئیچ SW3 برای ارسال frameها به سوئیچ root، می تواند از دو مسیر استفاده کند: مسیر مستقیم که از پورت G0/1 خارج می شود و به سوئیچ root می رسد، و مسیر غیر مستقیمی که از پورت G0/2 خارج می شود و از طریق SW2 به سوئیچ root می رسد. برای هر یک از پورت ها، هزینه ی رسیدن به سوئیچ root برابر است با مجموع هزینه ی خروج از پورت هایی که frame ارسالی، برای رسیدن به سوئیچ root از آن ها عبور می کند (در این محاسبه، هزینه ورود آن frame به پورت ها حساب نمی شود). همانطور که مشاهده می کنید، مجموع هزینه ی مسیر مستقیم که از پورت G0/1 سوئیچ SW3 خارج می شود برابر 5 است، و مسیر دیگر دارای مجموع هزینه ی 8 می باشد. از آنجایی که پورت G0/1، بخشی از مسیری است که هزینه ی کمتری برای رسیدن به سوئیچ root دارد، سوئیچ SW3 این پورت را به عنوان root port انتخاب می کند.
سوئیچ ها با سپری کردن فرایندی متفاوت به همین نتیجه می رسند. آنها هزینه خروج از پورت خود را به root cost موجود در Hello BPDU ورودی از همان پورت اضافه می کنند و هزینه رسیدن به سوئیچ root از طریق آن پورت را به دست می آورند. هزینه خروج از هر پورت در پروتکل STP یک عدد صحیح (integer) می باشد که به هر پورت در هر VLAN اختصاص می یابد، تا پروتکل STP با استفاده از این مقیاس اندازه گیری بتواند تصمیم بگیرد که کدام پورت را به توپولوژی خود اضافه کند. در این فرایند سوئیچ ها، root cost سوئیچ های مجاور را که از طریق Hello BPDUهای دریافتی به دست می آورند، بررسی می کنند.

تصویر 6-2 یک مثالی از چگونگی محاسبه بهترین root cost و سپس انتخاب آن به عنوان root port را نشان می دهد. اگر به تصویر توجه کنید، خواهید دید که سوئیچ root پیام هایی(Hello) که root cost آن ها برابر صفر می باشد را ارسال می کند. هزینه رسیدن به سوئیچ root از طریق پورت های سوئیچ root برابر با صفر است.
در ادامه به سمت چپ تصویر توجه کنید که سوئیچ SW3، root cost دریافتی از طریق SW1 را (که برابر صفر است) با هزینه ی خروج از پورت G0/1 که آن Hello را دریافت کرده (5) جمع می کند و هزینه ارسال اطلاعات از طریق این پورت را به دست می آورد.
در سمت راست تصویر، سوئیچ SW2 متوجه شده که root cost آن برابر با 4 است. پس زمانی که SW2 یک Hello برای SW3 ارسال می کند، مقدار root cost آن را 4 قرار می دهد. در سمت دیگرهزینه ارسال اطلاعات از طریق پورت G0/2 در سوئیچ SW3 برابر 4 است، از اینرو سوئیچ SW3 این دو مقدار را با هم جمع می کند و به این نتیجه می رسد که هزینه ی رسیدن به سوئیچ root از طریق پورت G0/2 برابر 8 است.
با توجه به نتایج به دست آمده از آنجایی که پورت G0/1 نسبت به پورت G0/2 هزینه ی کمتری برای رسیدن به سوئیچ root دارد، پس سوئیچ SW3 پورت G0/1 را به عنوان RP انتخاب می کند. سوئیچ SW2 نیزبا گذراندن همین فرایند پورت G0/2 را به عنوان RP انتخاب می کند. سپس تمام سوئیچ ها، root port های خود را در وضعیت forwarding قرار می دهند.
انتخاب Designated Port در هر LAN segment (پورت کاندید)
پس از انتخاب سوئیچ root، در سوئیچ های nonroot، تمام root portها را مشخص کردیم و آنها را در وضعیت forwarding قرار دادیم. مرحله نهایی پروتکل STP برای تکمیل توپولوژی STP، انتخاب designated port در هر LAN segment است. در هر بخش(segment) از LAN، پورت سوئیچی که کمترین root cost را دارد و به آن بخش از LAN متصل است Designated port )DP) نامیده می شود. زمانی که یک سوئیچ nonroot می خواهد که یک Hello را ارسال کند، هزینه رسیدن به سوئیچ root را در root cost آن پیام قرار می دهد و ارسال می کند. دراینصورت پورت سوئیچی که کمترین هزینه را برای رسیدن به root دارد، در میان تمام سوئیچ هایی که به آن بخش متصل هستند، به عنوان DP در آن بخش شناخته می شود. در این مرحله اگر هزینه سوئیچ ها برای رسیدن به سوئیچ root برابر بود، پورت سوئیچی که BID کمتری دارد را به عنوان DP انتخاب می کنیم.
در تصویر 4-2 پورت G0/1 در سوئیچ SW2 که به سوئیچ SW3 متصل است، به عنوان DP انتخاب می شود.
پس از انتخاب DPها، تمام آن ها را در وضعیت forwarding قرار می دهیم.
مثالی که در تصاویر 3-2 تا 6-2 به نمایش گذاشته شد، تنها پورتی که نیازی ندارد تا در وضعیت forwarding قرار بگیرد، پورت G0/2 در سوئیچ SW3 است. درنهایت فرایند پروتکل STP کامل شد و جدول زیر وضعیت نهایی هر پورت و علت قرار گرفتن در آن وضعیت را نشان می دهد:
به صورت خلاصه اگر بخواهیم توضیح دهیم، در فرایند اجرای پروتکل STP:
• در قدم اول سوئیچ root انتخاب می شود که ابتدا تمام سوئیچ ها سعی می کنند خود را به عنوان root معرفی کنند، سپس سوئیچی که رقم BID آن مقدار کمتری را داشته باشد به عنوان سوئیچ root انتخاب خواهد شد.
• در قدم دوم برای هر سوئیچ، پورتی که کمترین هزینه برای رسیدن به سوئیچ root دارد را به عنوان root port انتخاب می شود. سپس همه ی root portها را در وضعیت forwarding قرار می گیرند.
• در قدم سوم پورت های کاندید انتخاب می شوند و در وضعیت forwarding قرار می گیرند. در نهایت پورت هایی که وضعیتشان مشخص نشده در وضعیت blocking قرار می گیرند.